

It might not just be lemmy.world, but several times recently I’ve made posts (usually to !helldivers2.lemmy.ca) that I check throughout the day. Then like 8 hours after I’ve made the post, I’ll see comments appear from people on lemmy.world that are several hours old.
It seems like there can be a queue that gets build up and then is suddenly flushed.
I see it happening the other way as well. This morning I made a post from my sh.itjust.works account and then switched over to a lemmy.world account and can’t see it. So the delay is going both ways.
I’d like to celebrate early and possibly jinx myself in the process but the line is going down.
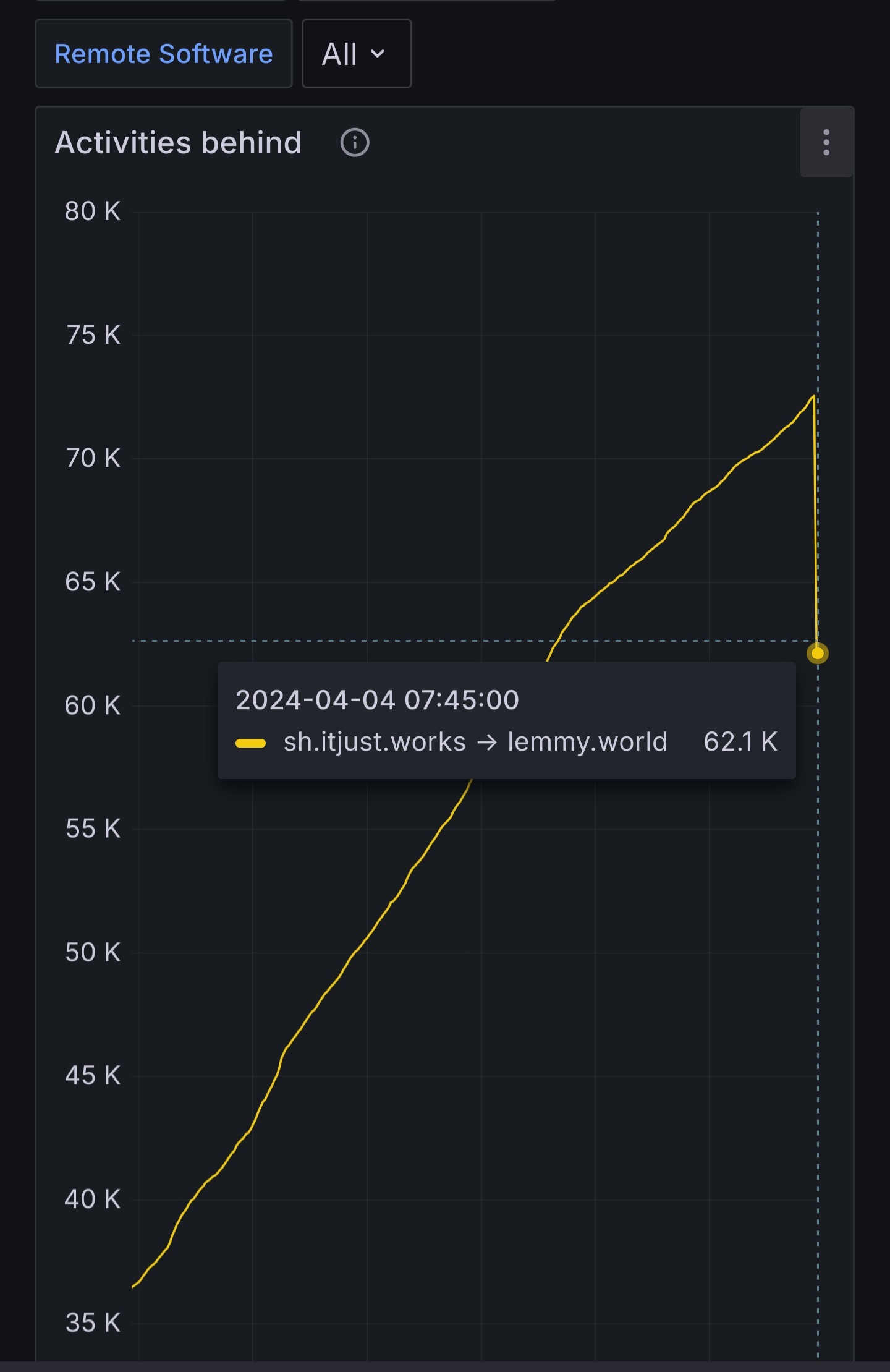
Lol the way that’s dropping I’d say a celebration is in order!
We are currently seeing a backlog in outbound federation towards lemmy.world.
Really, this graph says it all… 📈
I’ve restarted the containers, hoping it starts catching up.
Oh yeah, that looks pretty telling. Also, just wanted to say thanks for how awesome you guys are on the admin team. The work you guys do and how responsive you are is freaking impressive. Thanks!
Sadly that line keeps going up.
I don’t have much of an update but it’s really specific to outbound federation and just with lemmy.world.
ie: inbound works fine, outbound with other instances works fine.Hmm sounds like it’s a problem on the lemmy.world side then.
Not necessarily.
Thing is, after a few consecutive failures, the next retry is now in a while (later tonight).
This retry spacing at least explains why it hasn’t gone down after the restart
I’m experiencing the same and only noticed it when posting to lemmy.world communities. I’d navigate to their instance directly and see both comments that didn’t federate yet and my comment missing. I haven’t observed this on other instances though, lends me to believe this might be just a lemmy.world problem?
I think I saw somewhere that lemmy.world has grown way bigger than most other instances - probably because the name is less confusing to new users. I’m wondering if they’re running into scaling issues as a result.
Some of the instance admins have been poking at this lagging federation issue for a few weeks now, trying to figure it out.
The Reddthat admin noticed that Lemmy’s federation process can’t seem to meet demand in some cases. Reddthat has had trouble staying current with lemmy.world due to the network latency between Europe and Australia: https://sh.itjust.works/comment/9807807. I understand that lemmy.nz has seen this, too.
Another thing that has been noticed is spamming of actions from kbin instances. It looks like some process gets stuck in a loop on the kbin side. https://lemmy.world/comment/8961882
I’m sure there are other contributing problems that still aren’t well understood. This software is a work in progress, after all.
These posts are enlightening, I think reddthat is right lemmy will need to using batch messages on longer intervals soon, that’s pretty unsustainable in current form. What an interesting scaling issue to encounter.
I only have a delay when I’m using a VPN.
Interesting. I’m not using a VPN in my case.
Dbzer0 recently had issues with long federation queues with big instances, due to delays in database access caused by geographic distance between frontend and backend… maybe this might be caused by something similar…?
Interesting. So by having the database and front end servers in different data centers, they couldn’t keep up with all the requests from the big instances. Sounds like upgrading to Lemmy 0.19.3 changed how the federation queues worked, where it wasn’t a problem before. I wonder if something similar could be going on here.
This does happen from time to time where the federation queue gets overwhelmed, usually with Lemmy.world for whatever reason. It appears that our outbound federation queue is really backed up right now.
@InEnduringGrowStrong@sh.itjust.works just restarted the service so it may be working better now.
See our Matrix chat for more details.
Awesome, you guys rock!



