- 6 Posts
- 23 Comments



 0·2 months ago
0·2 months agoWhile true, it’s important to remember that 1.5 was the goal for 2050 (as a 30 year average). That seems fairly unlikely at this point
I would say yes, although there is the slim possibility that these few years are an outlier. No serious person should count on it, however, because the consequences of being wrong in spite of what we’re seeing are downright apocalyptic.
Damn it’s still wild to me that generating text is a solved problem.

To address the article a little more directly: it’s notable that the article begins with Sam Altman’s take on the subject. His feeling are based on two fundamentally flawed premises:
- These models MUST get bigger for the improvements that their users DEMAND.
- The only solution to any environmental criticism is FUSION. A technology that Altman has personally invested in.
2 is ridiculous just on the face of it, but I think folks may have a harder time understanding why 1 is problematic. It is true that OpenAIs business model essentializes the idea that these models can’t ever be run locally, but the incentive to use their cloud services are quickly diminishing as smaller, local models catch up. This cycle will likely continue until local models are good enough to serve the needs of the vast majority of people, especially as specialized hardware makes it’s way into more and more consumer devices.
The costs are significant and growing but we should put some things into perspective to really tackle the problem efficiently. As an individual heavy usage of these tools (something like 1000 images generated) is still roughly the same level of emissions as driving across town and generating text is pretty much negligible in all scenarios.
Where we really need to be concerned is video generation (which could easily blow current energy usage out of the water) and water usage in these massive data centers. However, most of the current research on the subject does a pretty poor job of separating water usage for “AI” and general usage. This is why the next step is enforcing transparency so we can get a picture of how things are shaping up as this technology develops.
All that said, there are some pretty low hanging fruit when it comes to improving efficiency. A lot of these models are essentially first-passes on a project and efficiency will improve simply as they start to target edge and local models. Similarly, these water cooling systems are predicated on some fairly wasteful ideas, namely that cool fresh water is abundant and does not warrant preservation. Simply factoring in that this is clearly no longer the case will go a long way towards reducing that usage.
 0·3 months ago
0·3 months agoPosted elsewhere: Really I mean anything more advanced than keyword filters and grouped feeds. Performance friendly NLP has come a long way since the advent of RSS
We don’t need to use that word here
Really I mean anything more advanced than keyword filters. Performance friendly NLP has come a long way since the advent of RSS
Does anybody have any recommendations for FOSS RSS readers with actual content surfacing features? So many RSS feeds are full of junk (this is particularly a problem with feeds with wildly disparate posting frequencies) and I’ve always felt they’d be a lot more useful if people were putting more effort into a modern way to sort through extremely dense feeds.
 0·3 months ago
0·3 months agoMaterial You is increasingly a requirement for me to even use an app on a regular basis.
Well there’s two relevant points there:
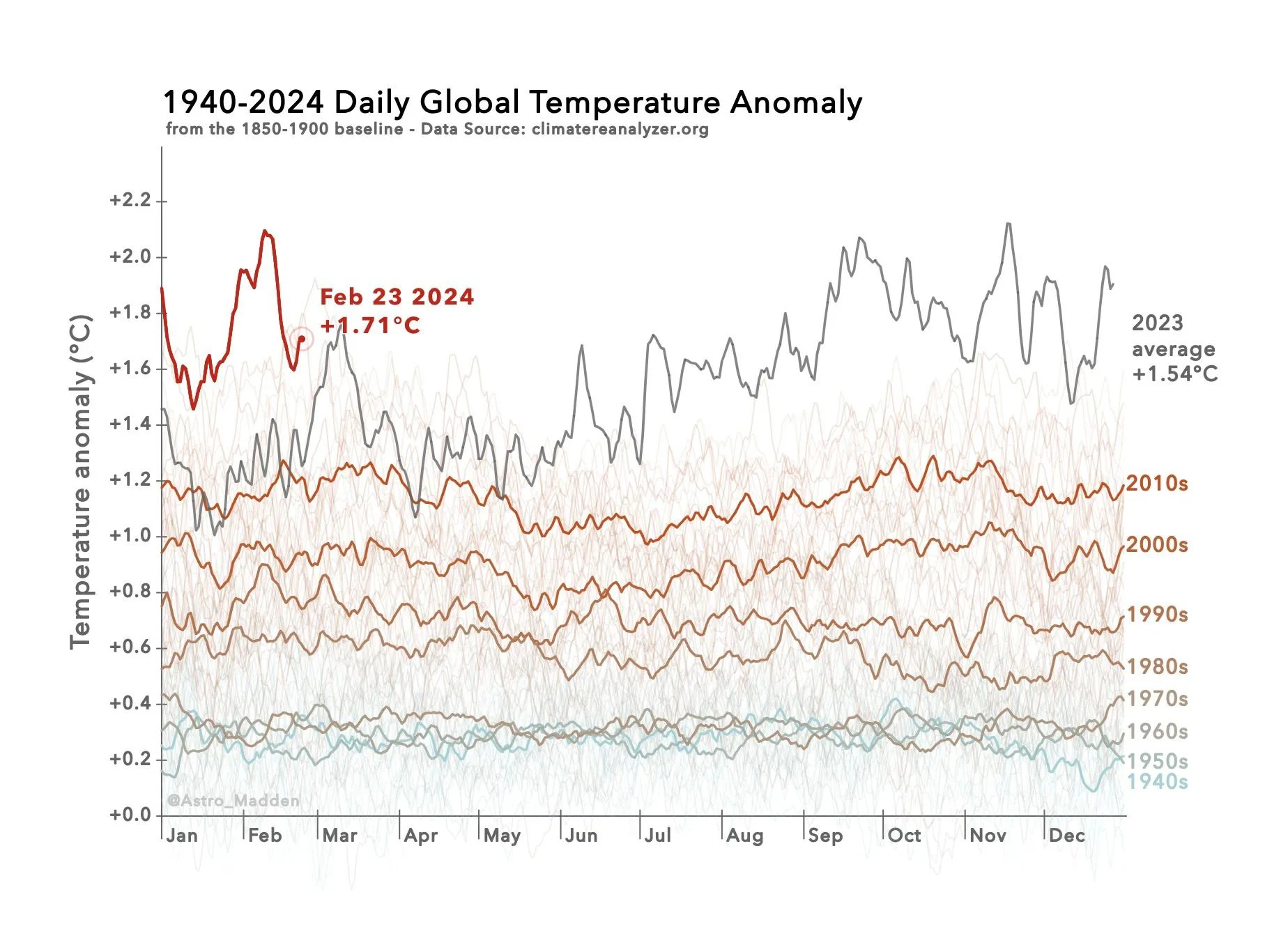
- The 1.5 degree warming targets set by the Paris Climate Accords are based on a 30 year average. One of the main points of the video and a recent popular point of conversation for climate communicators has been that this is simply too long a time span to be used as an actionable metric. This would mean that it would take at least 15 years of average temps being that high before it officially triggers anything.
- Current models absolutely suggest that period will start sometime in this decade, which was absolutely not the case for SOTA models in 2015
I mean actionable policy plans absolutely necessitate concrete goals. In this case, missing it seems to be more reflective of massive problems with our modeling than any sort of failure to act. When that goal was set absolutely nobody was seriously considering the possibility we would surpass it in the early 20s.

 0·3 months ago
0·3 months agoThey’ve got a long way to fall before they really must have a come to Jesus moment and more importantly they seem to think LLM search is a better bet. I really don’t think they’ve done anything to improve search on years.
They’re not even trying. They think of broken Internet they’ve created as market dominance
Thing is, it’s really not that cold. We’ve just forgotten how to deal with it.
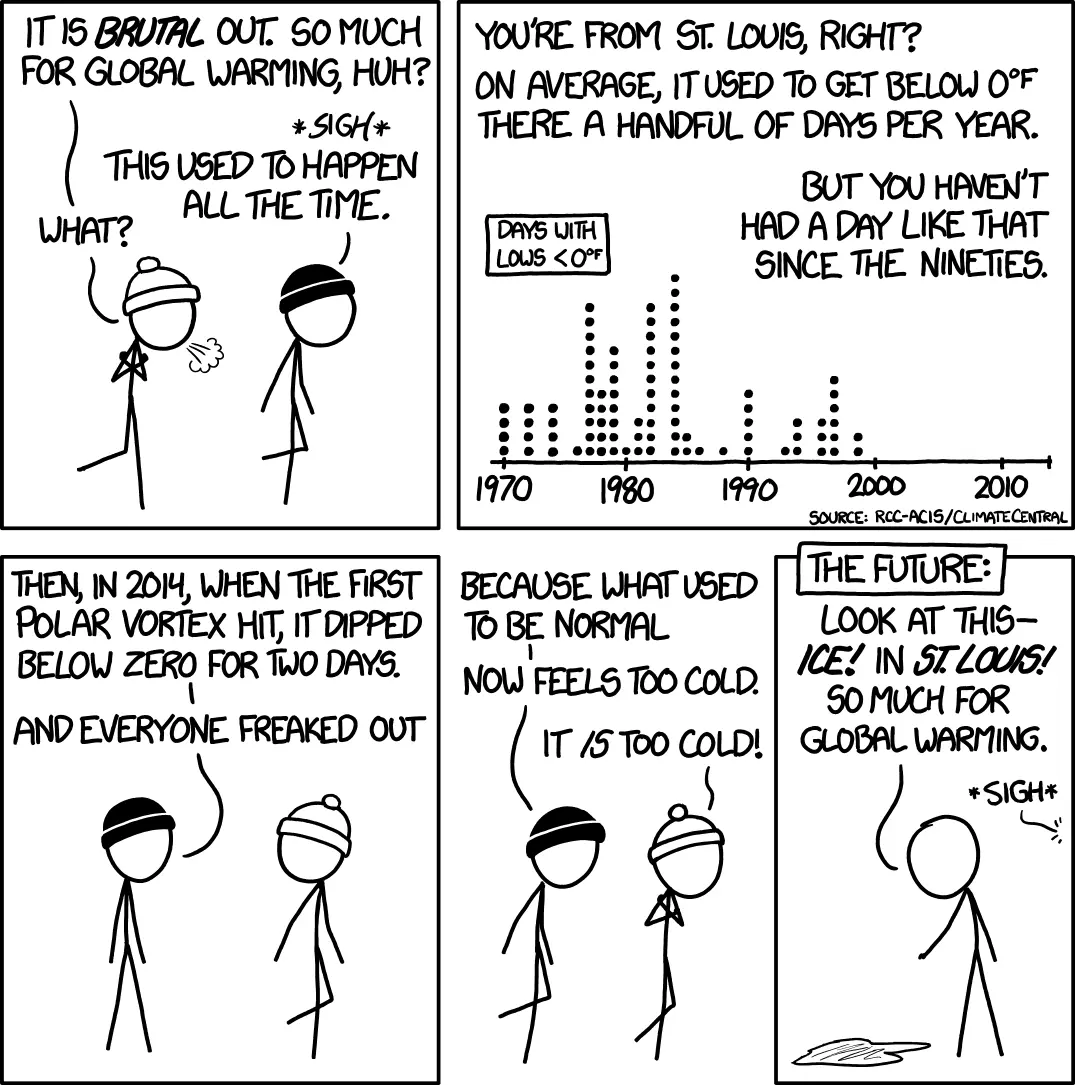
Granted the cold seems to be making it a lot farther south, but for most people this used to be normal.
Sam Altman is a clown. Nobody should trust this guy.
 0·4 months ago
0·4 months agoAny idea if these cores could be put to use?
 0·4 months ago
0·4 months agoGet involved with the DSA
Honestly I think reframing the project with a focus on reproducibility would go a long way. Feel like that was one of the major problems with the existing project

{kind=link}
Seems to me the most likely explanation is they got caught and fixed it.